최근 인스타그램에서 투자, 재테크, 심지어 성매매 관련 글들이 다양한 태그로 올라오는 경우가 많다. 인스타 피드의 본문에서 이런 이상한 태그를 가진 글들을 걸러주는 코드를 한번 만들어보았다. 아래의 코드를 기반으로 detect_ad라는 함수를 하나 추가해보려고 한다.
인스타그램 좋아요 봇 만들기 4 : 이미 좋아요 누른 피드가 많을때
지난 포스팅에서는 좋아요 봇의 오류를 처리하는 방법에 대해서 알아보았다. 이번에는 하나의 태그에서 이미 좋아요 누른 피드가 많아서 좋아요를 누르지 못하는 경우, 이를 처리하는 방법에
fecu.tistory.com
1. 인스타 광고 피드 분석
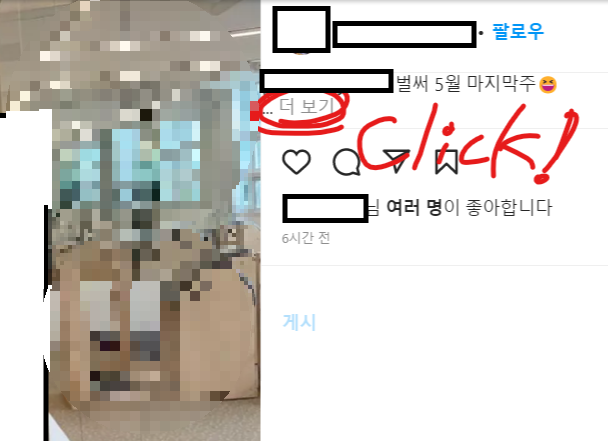
1) 피드 본문의 내용이 없는 경우
인스타 재테크 광고를 하는 계정들을 보면 피드 본문의 내용이 없는 경우가 있다. 이럴 경우 태그 검색에서 이 피드가 뜨지는 않을 것이므로 따로 분류하지 않아도 괜찮을 것 같았다.

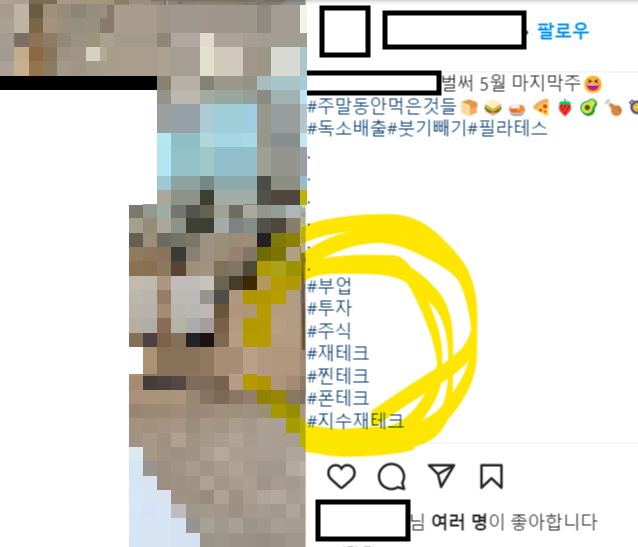
2) 피드의 글이 있는 경우
피드에 글이 있는 경우, 글이 짧으면 바로 모든 내용이 뜨지만 글이 길 경우에는 '더 보기'를 클릭해야 본문을 모두 볼 수 있었다. 그리고 본문 내에서 재테크, 폰테크, 투자 등 광고성 내용들이 포함되어 있었다. 이런 거지같은 피드들을 모두 걸러보려고 한다.
2. 인스타 본문 내용 긁어오기
먼저 셀레니움을 실행하여 인스타그램 본문의 태그를 찾아보자. driver.get('url')을 통해 태그로 들어간 뒤, 게시물을 클릭하고 본문을 살펴보았다.
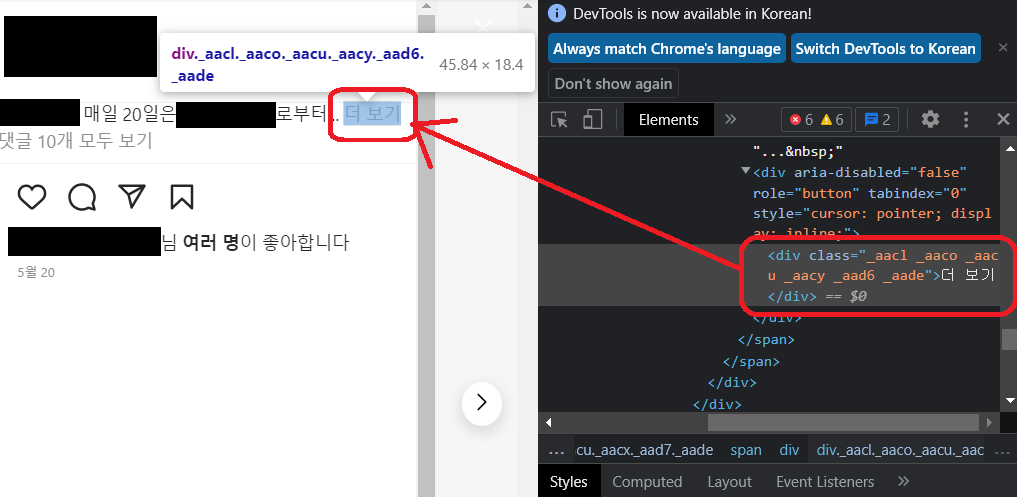
본문의 길이가 긴 경우 '더 보기' 버튼으로 글이 숨겨져 있었다.
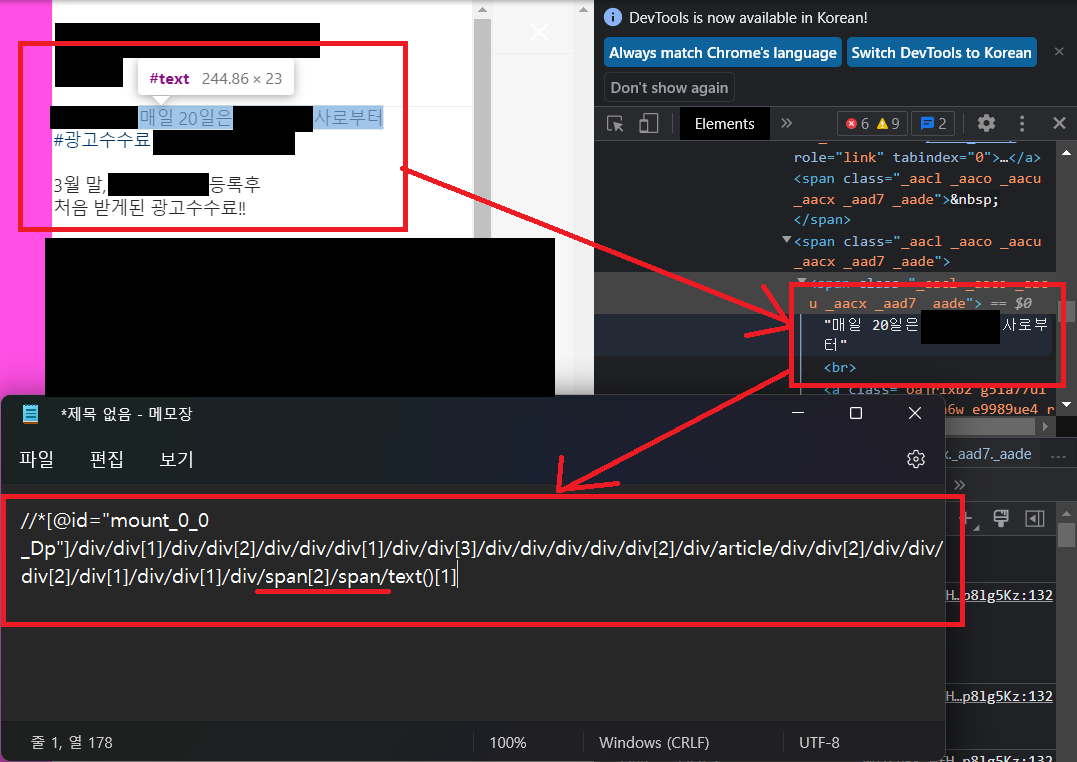
그리고 본문 내용의 XPath가 무척 길었는데, 자세히 보면 span태그가 2번 연속적으로 있다는 것을 알 수 있다.
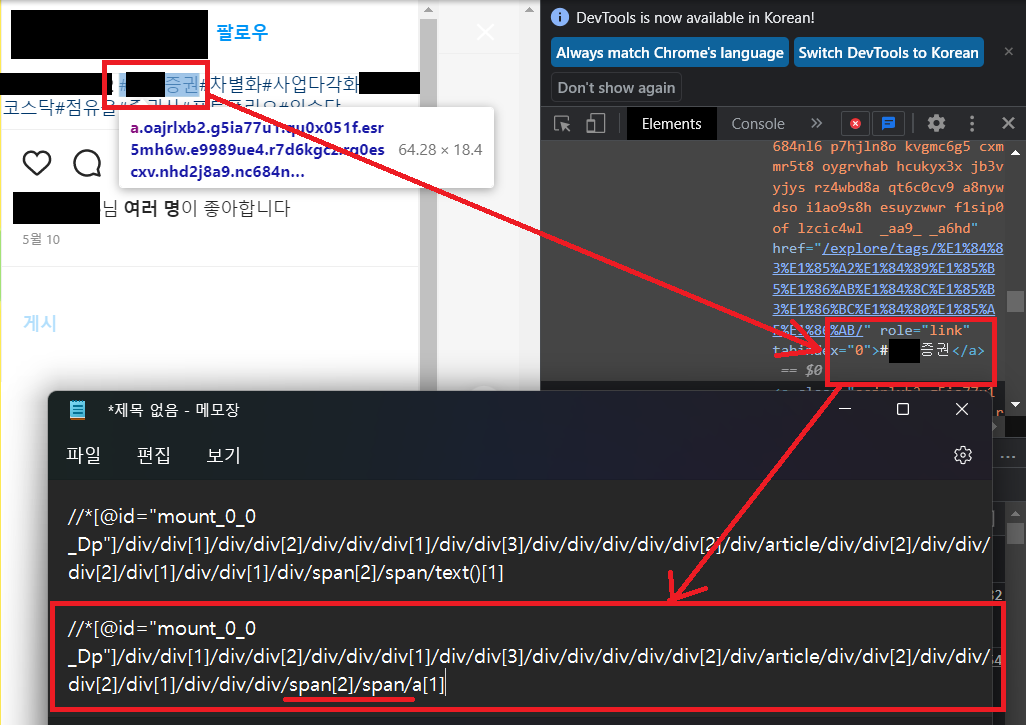
간혹 글의 길이가 짧을 경우 '더 보기' 버튼이 없었지만 본문 내용은 역시나 span 태그가 중복되는 것을 볼 수 있다. 따라서 더 보기 버튼을 누른 후 본문을 긁거나, 더 보기 버튼이 없을 경우에는 아무것도 하지 않고 본문을 긁도록 코드를 구현해보자. 참고로 이번 글의 XPath는 모두 상대경로이다.
def detect_ad():
ad_list = ['재테크', '투자', '부업', '집테크', '고수입', '수입', '억대연봉', '억대', '연봉', '순수익', '초기금액', '초기 금액', '금액', '입금']
try :
driver.find_element_by_xpath('//*[text() = "더 보기"]').click()
pass
except:
pass
texts = driver.find_elements_by_xpath('//span//span')
for text in texts :
article = text.get_attribute('innerText')
print(article)그리고 article 내부에서 ad_list 안의 항목이 존재하는지 찾고, 만약 광고가 들어 있다면 True를 반환하고 광고가 없다면 아무것도 반환하지 않는 것으로 코드를 완성해보자.
def detect_ad():
ad_list = ['재테크', '투자', '부업', '집테크', '고수입', '수입', '억대연봉', '억대', '연봉', '순수익', '초기금액', '초기 금액', '금액', '입금']
try :
driver.find_element_by_xpath('//*[text() = "더 보기"]').click()
pass
except:
pass
texts = driver.find_elements_by_xpath('//span//span')
for text in texts :
article = text.get_attribute('innerText')
for ad in ad_list :
if article.find(ad) == -1 :
continue
else :
print(f'광고 발견으로 통과합니다. 발견된 광고단어 : {ad}')
return True여기서 코딩이 끝날줄 알았으나.... 실행해보니 find 함수가 article 내부에서 ad_list를 실제로 찾지 못한다는 것을 발견했다. 열심히 구글링 한 결과, 한글에 대해 find함수가 제대로 작동하지 않는다는 것을 알게 되었다.
3. find 함수와 unicodedata 함수
파이썬에서 find함수를 이용해 한글을 찾을 경우, 내용이 같지만 다르게 인식될 수 있다고 한다. 자세한 내용은 아래 존슨유님의 글을 읽어보길 바란다.
[Python] 한글 내용이 같지만 다르다고 인식하는 경우
분석 환경 Google Colab pro의 구성환경 Python Version : 3.7.10 상황 눈으로 볼 땐 두 한글 변수의 값이 같지만 비교 연산자 실행 시 다르다고 인식하는 상황. 더 나아가 두 변수를 같게끔 인식 시키고 싶
jonsyou.tistory.com
위의 내용을 간략하게 이야기하면, 한글을 str로 인식할 경우 자음과 모음으로 분리되어 있다는 것이다. 실제로 a 안의 글들을 순차적으로 출력해보면 자음과 모음이 분리되어 있다는 것을 알 수 있다. 때문에 find함수로 article에서 광고 요소들을 찾을 수 없는 것이다.
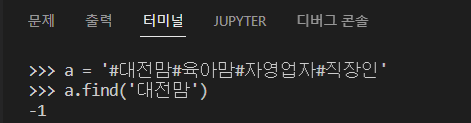
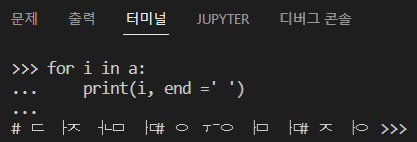
unicodedata모듈의 normalize 함수를 이용하면 자음과 모음을 합칠 수 있다. 이제 이것을 위의 코드에 적용해보자.
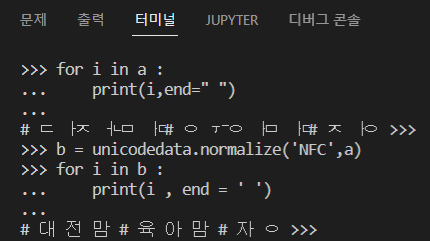
4. unicodedata.normalize() 함수 적용
위에서 짠 코드에서 unicodedata를 적용해보았다. 얻은 텍스트를 unicodedata 모듈로 자음과 모음을 합친 뒤, article이라는 변수에 넣어보았다.
def detect_ad():
ad_list = ['재테크', '투자', '부업', '집테크', '고수입', '수입', '억대연봉', '억대', '연봉', '순수익', '초기금액', '초기 금액', '금액', '입금']
try :
driver.find_element_by_xpath('//*[text() = "더 보기"]').click()
pass
except:
pass
texts = driver.find_elements_by_xpath('//span//span')
for text in texts :
article = unicodedata.normalize('NFC',text.get_attribute('innerText'))
for ad in ad_list :
if article.find(ad) == -1 :
continue
else :
print(f'광고 발견으로 통과합니다. 발견된 광고단어 : {ad}')
return True이제 전체 코드에서 unicodedata를 import하고 코드 내에서 작동하도록 하면 된다. 만약 detect_ad()가 True를 반환하면 '다음' 버튼을 누른 뒤 2초간 대기하고, 그렇지 않으면 좋아요를 누르고 넘어가는 것으로 likey() 함수를 수정해보았다.
def likey(insta_tag) :
like_cnt = random.randrange(20,30)
driver.get('https://www.instagram.com/explore/tags/{}/'.format(insta_tag))
time.sleep(random.randrange(5,15))
new_feed=driver.find_elements_by_class_name('_aagu')[9]
new_feed.click()
numoflike = 0
stop_num = 0
for i in range(like_cnt):
time.sleep(3)
span = driver.find_element_by_xpath('//*[@aria-label="좋아요" or @aria-label="좋아요 취소"]//ancestor :: span[2]')
like_btn = span.find_element_by_tag_name('button')
btn_svg = like_btn.find_element_by_tag_name('svg')
svg = btn_svg.get_attribute('aria-label')
if detect_ad() == True:
driver.find_element_by_xpath('//*[@aria-label="다음" and @height="16"]//ancestor :: div[2]').click()
time.sleep(2)
continue
elif svg == '좋아요' :
like_btn.click()
numoflike += 1
print('좋아요를 {}번째 눌렀습니다.'.format(numoflike))
time.sleep(random.randrange(50,70))
else :
print('이미 작업한 피드입니다.')
time.sleep(random.randrange(5))
stop_num += 1
if stop_num > 3:
print(f'좋아요 누른 태그가 {stop_num}개 중복됩니다.')
break
if i < like_cnt-1 :
next_feed_xpath = driver.find_element_by_xpath('//*[@aria-label="다음" and @height="16"]//ancestor :: div[2]')
next_feed = next_feed_xpath.find_element_by_tag_name('button')
next_feed.click()
time.sleep(random.randrange(5))그리고 일부러 순수익, 재테크 태그로 들어가 셀레니움을 돌려보니 잘 작동한다. 가끔 좋아요를 누르는 게시물이 있길래 확인해보니 본문이 아니라 댓글 안에 태그가 있는 것 같다. 그래도 이것으로 대부분의 광고들은 거를 수 있을 것으로 보인다.
5. 전체코드
아래는 전체 코드이다. 유용하게 쓰길 바란다. 다음에는 댓글에 있는 태그도 한번 처리해보고 싶다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from random import randrange, uniform, shuffle
import unicodedata
from selenium.webdriver.common.by import By
driver = webdriver.Chrome('chromedriver.exe')
# 자신의 아이디, 비밀번호 입력
yourid : str = "자신의 아이디"
yourpassword : str = "자신의 비밀번호"
# 좋아요를 1개 누르는 최소, 최대 시간 간격(1분 내외로 설정)
clickLikePauseMin : float = 50.0
clickLikePauseMax : float = 70.0
# 페이지 로딩까지 대기하는 시간(10초내외로 설정)
pageLoadingWaitMin : float = 3.0
pageLoadingWaitMax : float = 7.0
# 검색을 원하는 태그 입력
tags : list = ['원하는', '태그를', '리스트', '형태로 입력']
# 태그 하나당 좋아요를 누르는 최소, 최대 개수 설정
clickLikeInTagMin : int = 15
clickLikeInTagMax : int = 20
# 다음 태그로 넘어가는 쉬는 시간
tagIntervalmin : float = 300.0
tagIntervalmax : float = 1200.0
# 입력하고싶은 댓글 내용 입력
comments : list = ['♡', '원하는 댓글을', '리스트 형태로 입력', '우리 서로 맞팔해요~']
# 좋아요를 누른 총 개수 카운터(손대지 말 것)
totalLikeCount : int = 0
def login(id : str, password : str):
print('로그인 진행중...')
driver.implicitly_wait(6)
ur_id = driver.find_element(By.XPATH, '//input[@aria-label="전화번호, 사용자 이름 또는 이메일"]')
ur_id.send_keys(id)
# 아이디 입력 후 쉬는시간
time.sleep(uniform(1.0, 3.0))
ur_password = driver.find_element(By.XPATH, '//input[@aria-label="비밀번호"]')
ur_password.send_keys(password)
#비밀번호 입력 후 쉬는시간
time.sleep(uniform(1.0, 3.0))
ur_password.send_keys(Keys.ENTER)
#엔터키 입력 후 쉬는시간
time.sleep(uniform(pageLoadingWaitMin, pageLoadingWaitMax))
while True:
try:
islogin = driver.find_element(By.XPATH, f'//*[contains(@alt, "{yourid}")]')
print("로그인 완료")
break
except:
relogin = input('로그인에 실패했습니다. 수동으로 로그인 후 y를 눌러주세요.')
if relogin == 'y' or 'Y':
pass
def detect_ad():
ad_list = ['아이디 입력', '재테크', '투자', '부업', '집테크', '고수입', '수입', '억대연봉', '억대', '연봉', '순수익', '초기금액', '초기 금액', '금액', '입금']
article = driver.find_elements(By.XPATH, '//article//div[1]/span')
for texts in article :
text = unicodedata.normalize('NFC',texts.get_attribute('innerText'))
for ad in ad_list :
if text.find(ad) == -1 :
continue
else :
print(f'광고 발견. 발견된 광고단어 : {ad}')
return True
def click_likebtn(like_num : int, stop_num : int):
global totalLikeCount
like_btn = driver.find_element(By.XPATH, '//*[@aria-label="좋아요" or @aria-label="좋아요 취소"] //ancestor :: button')
like_svg = like_btn.find_element(By.TAG_NAME, 'svg').get_attribute('aria-label')
if like_svg == '좋아요' :
like_btn.click()
like_num += 1
totalLikeCount += 1
print(f'좋아요 {like_num}번째 : 좋아요 총 {totalLikeCount}개')
time.sleep(randrange(clickLikePauseMin, clickLikePauseMax))
return like_num, stop_num
else :
stop_num += 1
print(f'이미 좋아요 작업한 피드 : {stop_num}개 중복')
time.sleep(uniform(pageLoadingWaitMin, pageLoadingWaitMax))
return like_num, stop_num
def next_btn():
driver.find_element(By.XPATH, '//*[@aria-label="다음"] //ancestor :: button').click()
def bot(insta_tag : str, how_many : int):
print(f'작업 태그는 {insta_tag}입니다.')
driver.get(f'https://www.instagram.com/explore/tags/{insta_tag}/')
#페이지 로딩 대기
time.sleep(uniform(pageLoadingWaitMin, pageLoadingWaitMax))
new_feed = driver.find_elements(By.XPATH, '//article//img //ancestor :: div[2]')[9]
new_feed.click()
#페이지 로딩 대기
time.sleep(uniform(pageLoadingWaitMin, pageLoadingWaitMax))
like = 0
stop = 0
for click in range(how_many):
if detect_ad() == True:
next_btn()
#페이지 로딩 대기
time.sleep(uniform(pageLoadingWaitMin, pageLoadingWaitMax))
else :
like, stop = click_likebtn(like, stop)
next_btn()
#페이지 로딩 대기
time.sleep(uniform(pageLoadingWaitMin, pageLoadingWaitMax))
if stop >= 4 :
print(f'중복 피드가 많아 {insta_tag} 태그 작업 종료함')
return like
print(f'{insta_tag} 태그 작업완료')
return like
driver.get('https://instagram.com')
login(yourid,yourpassword)
shuffle(tags)
for tag in tags:
try :
bot(tag, randrange(clickLikeInTagMin,clickLikeInTagMax))
time.sleep(uniform(tagIntervalmin, tagIntervalmax))
except Exception as e :
print(e)
print('오류가 반복된다면 댓글로 문의해주세요.')
time.sleep(uniform(pageLoadingWaitMin, pageLoadingWaitMax))
driver.refresh()
driver.quit()


