최근에 티스토리에 백업 기능이 생겼다. 만약 티스토리 백업만을 원한다면 아래와 같이 들어가서 백업해보자.
티스토리 관리창 사이드바 최하단 --> 관리 / 블로그 --> 데이터관리 / 데이터 관리하기 --> 블로그 백업

카카오 화재로 인해 티스토리가 다운되는 현상을 지켜보면서, 어쩌면 내가 열심히 쓴 글들이 한순간에 모두 사라질 수도 있다는 어떤 불안감에 휩싸이게 되었다. 그래서 티스토리의 글들을 백업하여 네이버로 옮기거나 워드프레스, 구글블로그 같은 대안을 여러개 만들어놓아야 겠다는 생각이 들었다. 그 첫번째 단계는 티스토리 백업이었다.
1. 기존의 프로그램들 이용하기
티스토리 백업을 하기 위한 프로그램들을 이미 많은 분들이 만들어 놓았기 때문에, 이것을 이용하면 백업은 어렵지 않다. 하지만 이 블로그 까지 굴러 왔다면, 파이썬을 통해 직접 백업 코딩을 해보고 싶은 사람들일 것이다. 나 또한 나의 손으로 직접 백업을 해보고 싶었다. 그래도 혹시나 해서 아래에 여러 링크들을 첨부해둔다.
티스토리 블로그 백업 프로그램 v2.6, 무료 배포합니다!
티스토리 블로그는 백업 기능을 제공하지 않지만, Tistory Open API를 제공하는데요. 이 API를 이용하여 티스토리 백업 프로그램을 제작해 보았습니다. 해당 프로그램을 사용하여 여러분의 티스토리
luckygg.tistory.com
Tistory Saver 업데이트 내역
다운로드 : https://drive.google.com/file/d/1dy5_5C3FDgdFEY79i3rFWqXy4FNX8T9Q/view?usp=sharing설명 : https://neurowhai.tistory.com/297 v1.1.3.1- 로그인 안 되던 문제 수정.- 신규 에디터로 작성된 글의 이미지 일부 다운로드
neurowhai.tistory.com
티스토리 블로그 백업하기 & 워드프레스로 이사하기
티스토리 블로그 백업하기 & 워드프레스로 이사하기. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
jwFreeNote 5.10.11 메모 프로그램 업그레이드
메모 프로그램 jwFreeNote 5.10 release 11 jwFreeNote에서 노트를 수정하는 모드에서는 문서 작성에 도움을 드리기 위해 한글 모드인지 또는 영문 모드를 알려 주는 조그만 표시 기능인 한영 알리미가 있
badayak.com
2. 파이썬 코드 짜보기
1) 백업하기 쉬운 웹페이지 형식 찾기
막상 백업을 하려고 하니 가장 걸리적 거리는 것은 '내가 원하지 않는 소스'들이 백업파일에 포함되면서 파일이 굉장히 무거워지는 것이었다. 예를들면 티스토리 상하단의 광고라던지, 또는 좌측의 목차나 티스토리 로고 등 제거하고 싶은 요소들이 너무 많았다. 고민을 하다가 한때 카카오 화재 이후 자동으로 모바일 환경으로 접속되었던 것이 기억났다. 아래는 내가 쓴 블로그 글을 모바일로 백링크를 한 것이다.
부산 여행지 추천 : 영도 흰여울문화마을
오랜만에 집에 가서 어디 카페 갈만한 곳 없나 찾다가 요새 영도에 이쁜 카페가 많다는 말을 듣고 찾아가게 된 흰여울 문화마을 처음에는 그냥 카페만 찾았는데 어쩌다가 흰여울 문화마을로 가
fecu.tistory.com
모바일 환경은 데스크톱에 비해 광고의 수나, 제거해야할 요소들이 무척 적었다. 그래서 모바일 환경에서 백업을 진행하기로 했다. 호출한 모듈은 아래와 같다.
from selenium import webdriver
from selenium.webdriver.common.by import By
import urllib.request as req
import re
import time
import os
import ssl
# 인증서 문제 해결
ssl._create_default_https_context = ssl._create_unverified_context
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
options.add_argument('--no-sandbox')
options.add_argument("disable-gpu")
options.add_argument('window-size=1920x1080')
options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
driver = webdriver.Chrome(options = options)
2) 폴더 만들기
먼저 html파일과 이미지들을 저장할 폴더가 필요했다. 그래서 카테고리와 제목을 추출해서 그대로 폴더를 만들었다.

이 두개를 어떻게 크롤링할까 고민했는데 역시나 그냥 xpath를 그대로 복사하는게 편했다. find_element로 요소를 찾고, 간단하게 뒤에 .text를 쓰면 html 내부의 글자들을 모두 크롤링 해준다. 두 요소들을 변수에 담아보았다.
article_category = driver.find_element(By.XPATH, "//article//a//span[@class='inner_g']").text
title = driver.find_element(By.XPATH, "//h3[@class='tit_blogview']").text
문제는 제목 안에 특수문자가 여러개 들어있는 경우, 폴더를 만들수가 없었다. 그래서 re모듈을 활용해 특수문자들을 모두 치환해주었다. re.sub(변경하려는 특수문자, 치환문자, 변경 대상)으로 입력하면 특수문자가 치환된다.
new_title = re.sub(r"[^\uAC00-\uD7A30-9a-zA-Z\s]", "_", title)
이렇게 구한 두개의 변수를 활용해서 폴더를 만들었다. 파일의 경로가 자주 쓰이기 때문에 경로를 folder라는 변수에 넣어주었다. 그리고 파이썬 내부 모듈인 os를 이용했다. os.getcwd는 현재 파이썬이 실행중인 경로를 리턴하고, makedirs는 지정한 폴더를 한꺼번에 만들어준다. 만약 폴더가 있을 경우에는 오류를 반환하기 때문에 try와 except를 이용해 처리해주었다.
cwd = os.getcwd()
folder = f'{cwd}/backupfile/{article_category}/{new_title}'
try :
os.makedirs(f'{folder}')
except Exception as e :
print(e)
이제 이 폴더에 이미지 파일과 html을 차곡차곡 담으면 된다.
2) 이미지 긁어오기
백업할 것들 중 가장 중요한 것들은 이미지였다. 만약 티스토리가 사라진다면 내용은 새로 써도 괜찮지만, 이미지를 새로 구하는데는 더 많은 노력과 시간이 필요했다. 본문의 이미지들은 article 안의 img 태그 안에 들어있었다.
<!--이미지 xpath 상대경로-->
//*[@id="mainContent"]/div[3]/figure[3]/span/img
<!--이미지 xpath 전체 경로-->
/html/body/div[1]/main/section/div/article/div[3]/figure[3]/span/img
<!--요약해본 이미지 xpath경로-->
//article//img
위의 xpath를 활용하여 img태그들을 리스트에 담고, for문을 통해 이미지 소스(src)를 추출했다. 모바일 환경에서 진행을 하니, 스크롤을 하지 않은 부분은 로딩이 되지 않아 소스 추출이 어려웠기에 맨 아래까지 스크롤을 한 뒤 소스를 추출했다.
images = driver.find_elements(By.XPATH, "//article//img")
image_srcs = []
for img in images :
driver.execute_script("arguments[0].scrollIntoView({block : 'center'});", img)
src = img.get_attribute('src')
image_srcs.append(src)
그런데 이렇게 파일을 다운받으면 지도에 있는 이미지들까지 모두 다운이 됬다. 그래서 src내부에 map이나 ico_marker와 같은 요소들을 포함한 src들을 모두 제거해주었다.
for img in images :
driver.execute_script("arguments[0].scrollIntoView({block : 'center'});", img)
src = img.get_attribute('src')
if src.find("map") == -1 and src.find("ico_marker") == -1:
image_srcs.append(src)
그리고 urllib의 request 모듈을 활용해 이미지를 다운받았다. req.urlretrieve(이미지 소스, 저장할 경로와 이름)을 하면 이미지를 다운 받을 수 있다. 원래 대부분의 파일들은 jpg로 저장하면 문제가 없지만, gif나 png 같은 그림들을 그대로 저장하고 싶어서 split을 통해 이미지 소스의 마지막 확장자를 구하고, 이것을 활용해서 이미지를 그대로 저장했다.
if len(image_srcs) > 0:
i = 0
for image_src in image_srcs:
i += 1
image_extension = image_src.split(".")[-1]
try :
req.urlretrieve(image_src, f"{folder}/{new_title}{i}.{image_extension}")
except Exception as e :
print(e)
이렇게 하면 이미지를 저장할 수 있다. 이제 본문의 제목과 카테고리들을 활용해서 폴더를 만들고, 그 안에 html파일과 이미지들을 한꺼번에 저장하면 끝이난다.
3) HTML 소스 긁어오기
셀레니움에서 크롤링을 하는 방법은 무척 간단하다. 만약 크롬 웹드라이버가 driver로 정의되어 있다면 아래와 같은 명령으로 크롤링이 가능하다.
with open("원하는 제목.html", "w") as f:
f.write(driver.page_source)
f.close()
#혹시 위의 방식으로 html 파일이 열리지 않는다면 아래와 같이 쓰기
with open("원하는 제목.html", "w", -1, "utf-8") as f:
f.write(driver.page_source)
f.close()
이런 식으로 코드를 작성하면 페이지의 모든 html을 긁어오기 때문에, 실행시켰을 때 그냥 모바일로 접속한 것과 같은 환경이 보인다. 그런 점이 별로 마음에 들지 않아 정말 본문에 있는 내용들만 크롤링 하고 싶었다. 찾아보니 요소들은 아래와 같았다. 그래서 이를 찾아 xpath로 요소를 지정하고 저장했다.
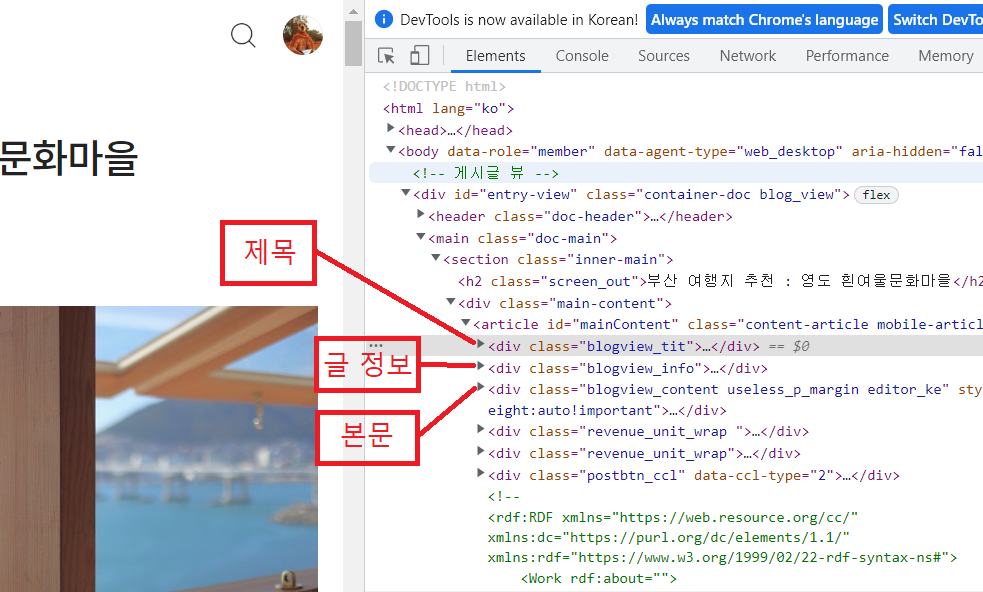
with open(f"{folder}/{new_title}.html", "w", -1, "utf-8") as f:
html_tit = driver.find_element(By.XPATH, "//*[@id='mainContent']/div[1]")
html_info = driver.find_element(By.XPATH, '//*[@id="mainContent"]/div[2]')
html_text = driver.find_element(By.XPATH, '//*[@id="mainContent"]/div[3]')
f.write(html_tit.text)
f.write(html_info.text)
f.write(html_text.get_attribute('innerHTML'))
f.close()
xpath로 찾은 요소 아래의 html을 긁어오고 싶으면 get_attribute('innerHTML')을 이용하면 된다. 그런데 이렇게 하니 css를 가져오지 못해 이미지 묶음들이 모두 해체됬다. 제목도 일반 본문과 같은 태그로 되어 있어 눈에 잘 띄지 않았다. 이것도 마음에 들지 않아서 html 앞부분에 여러가지것들을 포함해 보았다.
with open(f"{folder}/{new_title}.html", "w", -1, "utf-8") as f:
f.write('<!DOCTYPE html>')
f.write('<html lang="ko">')
f.write('<head>')
f.write('<meta charset="UTF-8">')
f.write('<meta http-equiv="X-UA-Compatible" content="IE=edge">')
f.write('<meta name="viewport" content="width=device-width, initial-scale=1.0">')
f.write('<link rel="stylesheet" href="https://tistory1.daumcdn.net/tistory_admin/assets/blog/tistory-kore-11da4a9fb29914e239921e4a4df9397a3471f964/dist/mobile/style/t.main.css">')
f.write('<link rel="stylesheet" href="https://tistory1.daumcdn.net/tistory_admin/assets/blog/tistory-kore-11da4a9fb29914e239921e4a4df9397a3471f964/dist/mobile/style/t.article.css">')
f.write('</head>')
f.write('<style type="css/text">')
f.write('p{font-size: 1.5rem;}')
f.write('</style>')
html_tit = driver.find_element(By.XPATH, "//*[@id='mainContent']/div[1]")
html_info = driver.find_element(By.XPATH, '//*[@id="mainContent"]/div[2]')
html_text = driver.find_element(By.XPATH, '//*[@id="mainContent"]/div[3]')
f.write('<h1>')
f.write(html_tit.text)
f.write('</h1>')
f.write('<h2>')
f.write(html_info.text)
f.write('</h2>')
f.write(html_text.get_attribute('innerHTML'))
f.close()
4) 본문만 저장하기
나중에 글을 옮기려고 할 때는 본문만 있는 것이 더 편할 것 같았다. 그래서 제목, 정보, 본문을 텍스트문서로 하나 더 저장해 주었다.
with open(f"{folder}/{new_title}.txt", "w", -1, "utf-8") as f:
html_tit = driver.find_element(By.XPATH, "//*[@id='mainContent']/div[1]")
html_info = driver.find_element(By.XPATH, '//*[@id="mainContent"]/div[2]')
html_text = driver.find_element(By.XPATH, '//*[@id="mainContent"]/div[3]')
f.write(html_tit.text)
f.write(html_info.text)
f.write(html_text.text)
f.close()
3. 함수 만들기 및 전체코드
위의 코드들을 모아서 backup이라는 함수를 만들어 보았다. backup은 num이라는 인자를 받아서 파일들을 백업한다. 이제 이 함수를 for문을 통해 돌려주면 백업이 완료된다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import urllib.request as req
import re
import time
import os
import ssl
# 인증서 문제 해결
ssl._create_default_https_context = ssl._create_unverified_context
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
options.add_argument('--no-sandbox')
options.add_argument("disable-gpu")
options.add_argument('headless')
options.add_argument('window-size=1920x1080')
options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
driver = webdriver.Chrome('크롬 웹드라이버 주소', options = options)
def backup(num) :
driver.get(f"https://"+"자기 아이디"+".tistory.com/m/{num}")
time.sleep(3)
# 카테고리와 제목 가져오기
try :
article_category = driver.find_element(By.XPATH, "//article//a//span[@class='inner_g']").text
except Exception as e:
return print(e)
article_category = driver.find_element(By.XPATH, "//article//a//span[@class='inner_g']").text
title = driver.find_element(By.XPATH, "//h3[@class='tit_blogview']").text
new_title = re.sub(r"[^\uAC00-\uD7A30-9a-zA-Z\s]", "_", title)
# 이미지 끌어오기
images = driver.find_elements(By.XPATH, "//article//img")
image_srcs = []
for img in images :
driver.execute_script("arguments[0].scrollIntoView({block : 'center'});", img)
src = img.get_attribute('src')
if src.find("map") == -1 and src.find("ico_marker") == -1:
image_srcs.append(src)
# 저장하기
cwd = os.getcwd()
folder = f'{cwd}/backupfile/{article_category}/{num}번_{new_title}'
try :
os.makedirs(f'{folder}')
except Exception as e :
print(e)
with open(f"{folder}/{new_title}.html", "w", -1, "utf-8") as f:
f.write('<!DOCTYPE html>')
f.write('<html lang="ko">')
f.write('<head>')
f.write('<meta charset="UTF-8">')
f.write('<meta http-equiv="X-UA-Compatible" content="IE=edge">')
f.write('<meta name="viewport" content="width=device-width, initial-scale=1.0">')
f.write('<link rel="stylesheet" href="https://tistory1.daumcdn.net/tistory_admin/assets/blog/tistory-kore-11da4a9fb29914e239921e4a4df9397a3471f964/dist/mobile/style/t.main.css">')
f.write('<link rel="stylesheet" href="https://tistory1.daumcdn.net/tistory_admin/assets/blog/tistory-kore-11da4a9fb29914e239921e4a4df9397a3471f964/dist/mobile/style/t.article.css">')
f.write('</head>')
f.write('<style type="css/text">')
f.write('p{font-size: 1.5rem;}')
f.write('</style>')
html_tit = driver.find_element(By.XPATH, "//*[@id='mainContent']/div[1]")
html_info = driver.find_element(By.XPATH, '//*[@id="mainContent"]/div[2]')
html_text = driver.find_element(By.XPATH, '//*[@id="mainContent"]/div[3]')
f.write('<h1>')
f.write(html_tit.text)
f.write('</h1>')
f.write('<h2>')
f.write(html_info.text)
f.write('</h2>')
f.write(html_text.get_attribute('innerHTML'))
f.close()
with open(f"{folder}/{new_title}.txt", "w", -1, "utf-8") as f:
html_tit = driver.find_element(By.XPATH, "//*[@id='mainContent']/div[1]")
html_info = driver.find_element(By.XPATH, '//*[@id="mainContent"]/div[2]')
html_text = driver.find_element(By.XPATH, '//*[@id="mainContent"]/div[3]')
f.write(html_tit.text)
f.write(html_info.text)
f.write(html_text.text)
f.close()
if len(image_srcs) > 0:
i = 0
for image_src in image_srcs:
i += 1
image_extension = image_src.split(".")[-1]
try :
req.urlretrieve(image_src, f"{folder}/{new_title}{i}.{image_extension}")
except Exception as e :
print(e)
#원하는 범위 내에서 for문을 돌림
for i in range(1, 101):
backup(i)
driver.quit()
5. 후기
이 코드를 이용하면 내 티스토리에 트래픽이 조금 걸리는 문제가 있다. 하지만 어차피 방문자 수가 그리 많지는 않기 때문에 별 문제는 없었던 것 같다. 티스토리를 이렇게 백업을 해두고 나니 마음이 좀 안정이 된다.
이 글들 중 일부는 네이버 블로그로, 일부는 구글 블로그로 이전할 것이다. 티스토리에만 의존해오고 있던 나에게, 이번 카카오 화재 사태는는 하나의 블로그에만 의존하는 것이 얼마나 위험한 것인지를 알게 해주었다. 그리고 카카오에 대한 굳건한 믿음을 깨뜨려 주었다. 어쨌든 이 글이 여러분들의 코딩에 도움이 되길 바란다. 그럼 끝.


