이번 글에서는 데이터 처리를 위한 도구인 Pandas에 대해 다루어 보려고 한다. 데이터 시각화를 위한 환경구성이 되어 있지 않다면 아래의 글을 참고바란다.
파이썬 데이터 시각화 입문 1 : 여는 글
이번에 좋은 기회가 있어서 파이썬을 활용한 데이터 시각화 수업을 하게 되었다. 수업 때 쓴 자료가 한번 쓰고 버리기에는 너무 아까워서 블로그에 남겨보려고 한다. 이 글의 목표는 파이썬의 fo
fecu.tistory.com
1. Pandas란?
판다스는 데이터 조작 및 분석을 위한 라이브러이다. 리스트나 딕셔너리를 표로 만들어 처리할 수 있다.

예를들어 아래와 같이 내부에 3개의 리스트가 들어 있는 리스트가 있다고 하자.
lstInLst = [[1,2,3],[4,5,6],[7,8,9]]
이 자료를 표현 방법만 바꾸면 아래와 같은 형태가 된다. 얼핏 보면 뭔가 표처럼 생겼다.
lstInLst = [[1,2,3],
[4,5,6],
[7,8,9]]
이제 이 자료를 판다스로 바꿔주면 ...
import pandas as pd
df = pd.DataFrame(lstInLst)
print(df)
아래와 같이 표의 형태가 된다. 이러한 판다스 데이터 타입을 데이터 프레임이라고 한다.
이제 이 자료는 행에 따라, 열에 따라 처리할 수 있다. 이해하기 어렵다면 엑셀과 비슷하다고 생각해도 좋다. 이제 대략적인 기능들을 알아보자.
2. 기본적인 pandas 사용법
위에서 판다스는 엑셀과 비슷하다고 했다. 따라서 판다스를 사용할 때 익혀야 할 기능은 엑셀을 사용할 때 익히는 기능과 동일하다.
일반적으로 엑셀을 쓸 때 가장 중요한 기능들은 자료 확인, 정렬, 원하는 셀 복사 등이다. 이러한 내용을 위주로 Pandas를 맛보기만 해보자.
데이터는 아래에 첨부파일로 두었다. 대략 11개의 행과 5개의 열이 들어있는 데이터이다. 이것을 써도 좋고, 스스로 만들어 써도 관계없다.
1) 모듈 호출 및 파일 불러오기(read_excel)
먼저 해당 파일의 경로에 데이터, 주피터 노트북 파일을 함께 넣어놓자.
그리고 아래와 같이 코드를 입력해주자. 코드에 대한 설명은 주석으로 달아 놓았다.
# pandas 를 pd라는 이름으로 호출
import pandas as pd
# 같은 폴더 안에 workout이라는 엑셀을 불러와 df라는 변수에 담음
df = pd.read_excel("./workout.xlsx")
# df 변수를 호출하여 확인
df
그리고 df를 확인해보면 아래와 같이 데이터가 들어가 있는 것을 확인해 볼 수 있다. 원래는 print(df)를 써야하지만, 주피터 노트북에서는 변수를 입력하는 것 만으로도 바로 값을 확인할 수 있다. 이제 이 데이터를 씹고 뜯고 맛보고 즐겨보자.
2) 조회(head, tail, index, columns)
현재는 데이터가 적어서 모두 띄워주지만, 데이터가 많으면 한번에 보기 어렵다. 이럴 경우는 head, tail 함수와 index를 통해 값을 대략적으로 확인해 볼 수 있다.
(1) head
head는 최상단의 데이터를 출력해준다. 상단의 [+ 코드] 를 누르면 입력창이 하나 추가된다.
여기에 하단의 코드를 입력해보자.
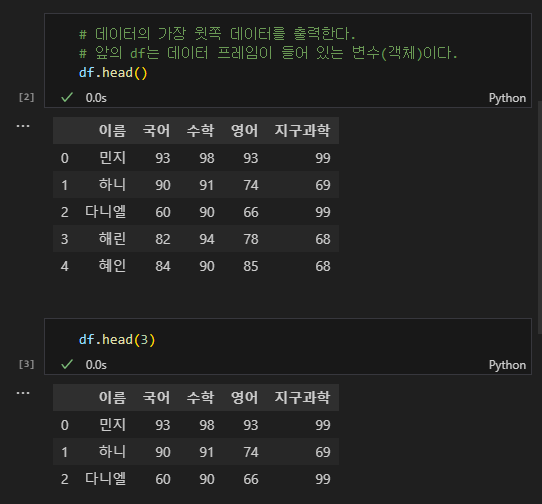
# 데이터의 가장 윗쪽 데이터를 출력한다.(기본 5행)
# 앞의 df는 데이터 프레임이 들어 있는 변수(객체)이다.
df.head()
# 뒤의 괄호 안에는 조회하고자 하는 행의 수를 입력한다.
df.head(3)
아래와 같은 출력이 뜬다면 성공이다. 이런 방식으로 데이터의 일부를 확인해 볼 수 있다.
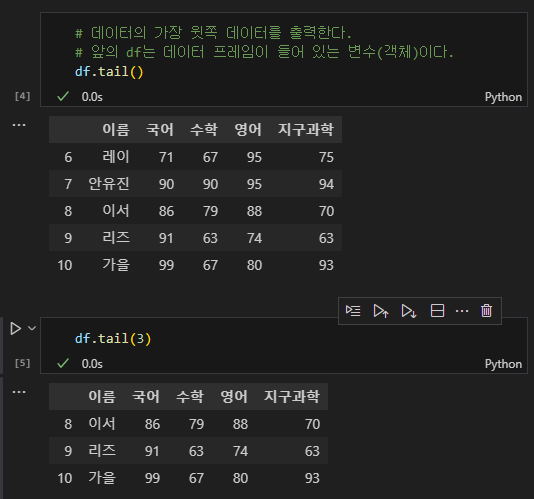
(2) tail
tail은 제일 끝에 있는 데이터를 확인해준다. 기본적으로 5개를 출력하지만, 괄호 안에 값을 입력하면 그 수만큼 출력해준다. head와 마찬가지이다.
# 데이터의 가장 하단 데이터를 출력한다.
df.tail()
# 괄호 안에는 조회를 원하는 행의 수를 입력한다.
df.tail(3)
초보자를 위해 설명하자면 괄호 안에 넣어주는 값을 파라미터라고 한다.
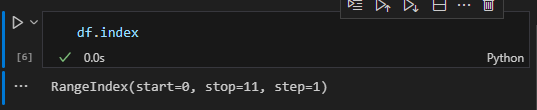
(3) index
index는 데이터의 개수, 그리고 형태를 간단하게 출력해준다. 대략적인 데이터의 양을 확인하고 싶을 때 유용하다.
df.index
3) 정렬(sort_values, sort_index, reset_index)
(1) sort_values
sort_values는 값의 오름차순, 혹은 내림차순으로 데이터를 정렬한다. 객체를 담은 변수 뒤에 아래와 같은 형태로 입력하면 간단하게 정렬이 가능하다.
# 변수명.sort_values("열이름")
df.sort_values("이름")
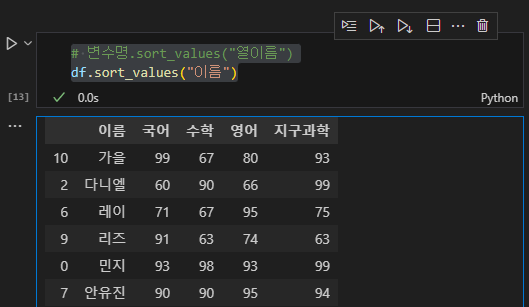
2개 이상의 열에서 정렬을 하고 싶다면 괄호 안에 리스트 형태로 열의 이름을 입력해주면 된다.
# 입력한 리스트가 ["수학". "이름"] 이라면
# 이름으로 정렬한 뒤 수학 점수로 정렬한다.
# 리스트에서 앞에 있을수록 정렬의 우선순위가 높다.
df.sort_values(["수학","이름"])
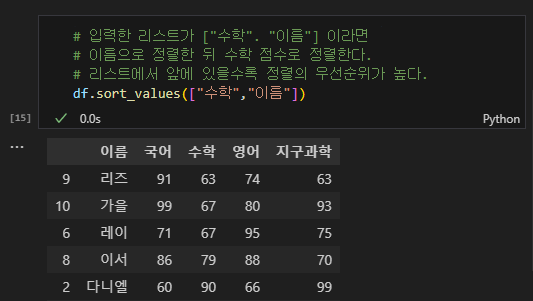
기본적으로 정렬은 오름차순이다. 만일 내림차순으로 정렬하고 싶다면 파라미터를 하나 더 입력하면 된다.
# ascending 을 False로 주면 내림차순으로 정렬된다.
# 리스트 앞에 by=[] 를 줘서 파라미터의 역할을 정확하게 표현할 수도 있다.
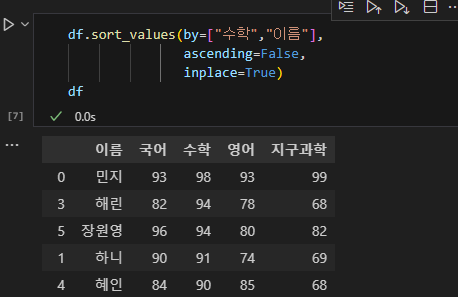
df.sort_values(["수학","이름"], ascending=False)
df.sort_values(by=["수학","이름"], ascending=False)
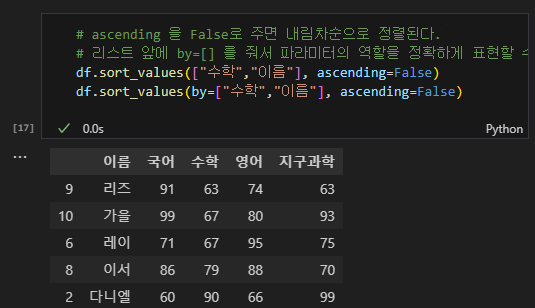
참고로 이렇게 한 뒤, 원래의 데이터를 확인해보면 처음과 같은 것을 볼 수 있다. 이것은 정렬된 데이터를 df에 다시 할당하지 않았기 때문에 생기는 문제이다.
해결방법은 두 가지가 있다.
- 새로운 변수에 할당한다
- inplace = True 라는 파라미터를 추가한다.
새로운 변수를 추가하면 아래와 같이 될 것이다.
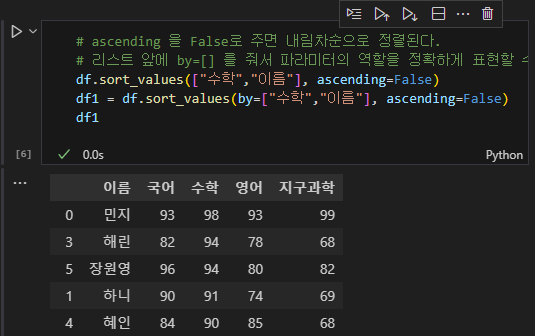
inplace=True라는 파라미터를 추가할 경우에는 기존의 변수가 덮어쓰기 된다.
(2) sort_index
sort_index는 말 그대로 인덱스에 따라 정렬한다. 아래와 같이 코드를 입력해보자.
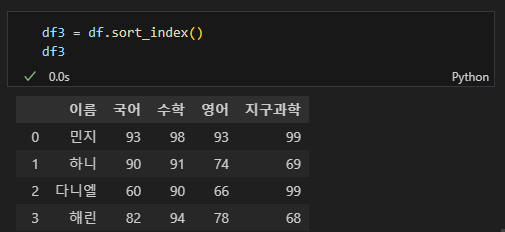
# 새로운 변수에 할당할 경우
df3 = df.sort_index()
df3
# inplace 파라미터를 이용할 경우
df.sort_index(inplace=True)
df
출력을 보면 인덱스에 따라 처음과 같이 정렬된 것을 볼 수 있다.
(3) reset_index
reset_index는 인덱스를 새롭게 지정한다. sort_values를 통해 정렬을 한 뒤, 새롭게 인덱스를 지정할 때는 아래와 같이 코드를 입력한다.
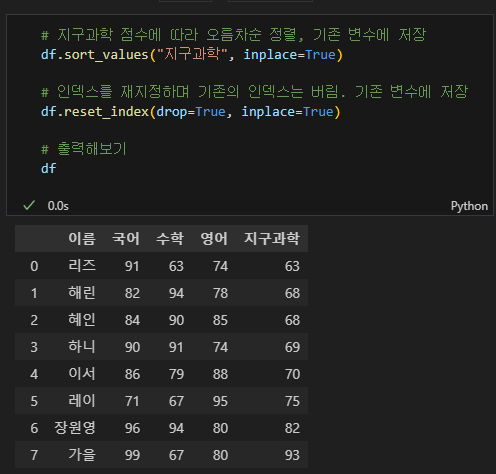
# 지구과학 점수에 따라 오름차순 정렬, 기존 변수에 저장
df.sort_values("지구과학", inplace=True)
# 인덱스를 재지정하며 기존의 인덱스는 버림. 기존 변수에 저장
df.reset_index(drop=True, inplace=True)
# 출력해보기
df
아래와 같이 지구과학 점수에 따라 오름차순으로 배열 된 뒤 인덱스가 재지정 된 것을 알 수 있다. 만일 기존의 인덱스를 남겨두고 싶다면 파라미터 drop을 없애주면 된다.
4) 삭제(drop, dropna)
(1) drop
해당 함수는 원하는 행이나 열을 삭제할 때 사용한다. 삭제할 index 와 columns를 파라미터로 받는다. 찾아보면 axis 등 다양한 방법으로 삭제가 가능하지만, 쓰다보면 알기쉽고 자기가 편한걸 쓰게 된다.
#drop은 파라미터로 여러가지를 받지만, index와 columns로 하는 것에 가장 편하다.
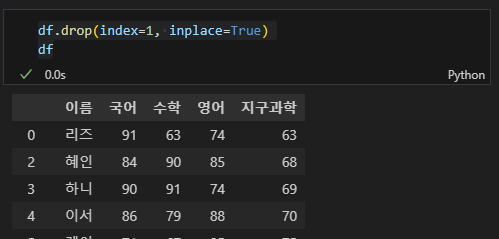
# 2번째 행 삭제
df.drop(index=1, inplace=True)
df
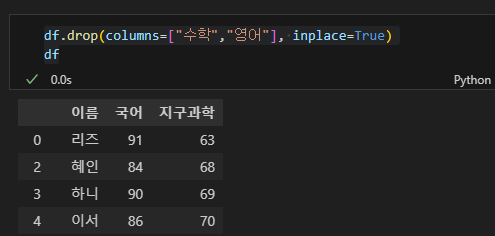
# 수학, 영어 열 삭제
df.drop(columns=["수학","영어"], inplace=True)
df
먼저 인덱스가 1인 행을 삭제해보면 아래와 같이 출력된다.
이번에는 수학, 영어 열을 지워보자. 파라미터로 columns를 주고 리스트 형태로 값을 입력하면 된다.
(2) dropna
dropna는 값이 없는 행을 제거한다. 보통 결측값 제거라고 말한다. numpy를 이용해 임시로 임의의 결측값을 만들어 보았다. 아래의 코드는 잘 몰라도 된다. 대충 4번째 행, 3번째 열의 값을 결측값으로 바꾸는 코드이다.
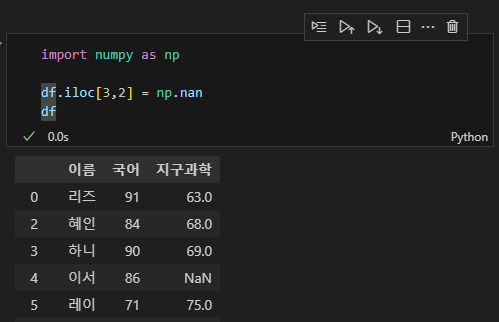
데이터를 호출했는데 NaN이라고 뜨면 저 값은 누락된 것이다. Not a Number의 약자이다. 이제 값이 없는 행을 제거해보자.
df.dropna(inplace=True)
df
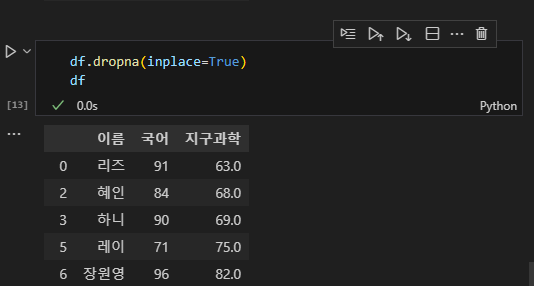
지구과학 성적이 없는 '이서'가 지워진 것을 확인할 수 있다. 혹은 NaN 값을 0이나 다른 숫자로 치환할 수도 있다. 여기서는 그런 수준 까지는 다루지 않겠다.
5) 행렬추출(loc, iloc, 쉬운 방법)
데이터를 사용할 때, 원하는 행이나 열 만을 이용할 수 있다. 이 때는 loc과 iloc을 이용한다.
(1) loc
loc은 location의 약자이다. loc 뒤에 딕셔너리의 키값을 입력하듯이 행과 열의 범위를 입력해주면 된다.
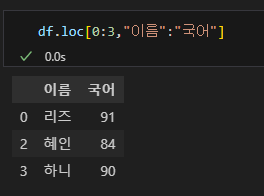
# df.loc[행 인덱스 범위, 열 인덱스 범위]
df.loc[0:3,"이름":"국어"]
df
인덱스와 열을 해당 이름 그대로 입력하면 된다. 현재는 행의 인덱스가 숫자, 열의 인덱스는 한글이기에 이렇게 입력하면 해당 범위까지 출력해준다.
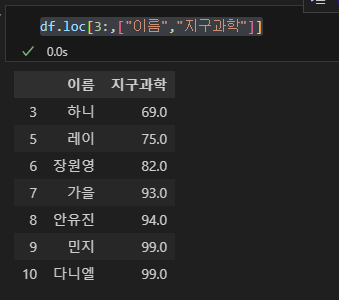
만일 인덱스가 3인 행부터의 이름, 지구과학 출력하고 싶다면 아래와 같은 방식으로 입력할 수 있다.
df.loc[3:,["이름","지구과학"]]
df
연속된 데이터는 콜론(:)을 이용해서 입력하고, 불연속적인 데이터는 리스트 형태로 입력하면 된다.
(2) iloc
iloc은 integer location의 약자이다. loc과 기능은 동일하지만 행과 열의 위치를 숫자로 받는다. 예를들어 위와 같은 방식으로 인덱스가 3행인 부터의 이름, 지구과학을 출력하고 싶다면 아래와 같이 입력한다.
df.iloc[2:,[0,2]]
df
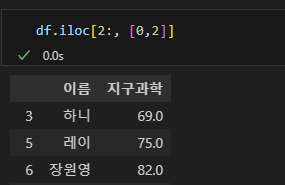
잘 본다면 loc 에서는 행의 파라미터를 3을 입력했고, iloc에서는 행의 파라미터를 2로 입력한 것을 볼 수 있다.
loc 에서는 인덱스가 3인 행부터 출력을 해준 것이고, iloc 에서는 0번째 행, 1번째 행을 지나 2번째 행부터 출력한 것이다.
(3) 쉬운 방법
변수 뒤쪽에 단순히 딕셔너리 형태로 괄호[] 를 붙여서 데이터를 조회할 수도 있다. 만일 0~3행, 이름과 지구과학 열을 보고싶다면 아래와 같이 입력할 수 있다.
# 변수 뒤에 단순하게 []만 이용하여 데이터를 조회할 수도 있다.
df[0:4][["이름","지구과학"]]
df
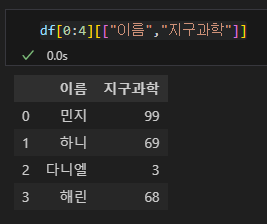
이번에는 이름을 한번 조회해보자. 이름이 있는 열의 인덱스는 "이름"이므로 아래처럼 간단하게 입력할 수 있다.
df["이름"]
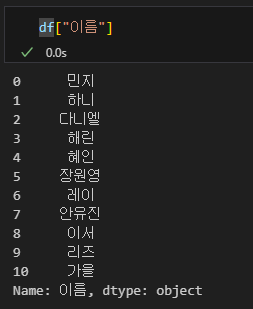
하다보면 알게 되겠지만 이 방식은 데이터를 변경하려고 할 때 오류를 불러일으킬 수도 있다. 따라서 값을 변경하려고 한다면 loc이나 iloc을 이용하길 권한다.
6) 조건문
(1) 단일 조건문
조건문은 원하는 조건에 맞는 데이터를 찾아준다. 엑셀의 필터 기능과 똑같다고 생각하면 된다. 만일 지구과학이 90점을 넘는 학생을 찾아 본다고 하면 아래와 같이 입력해볼 수 있다.
df["지구과학"] > 90
이렇게 입력할 경우 테이블 내의 모든 셀을 순회하며 조건에 대한 True, False 값을 반환한다.
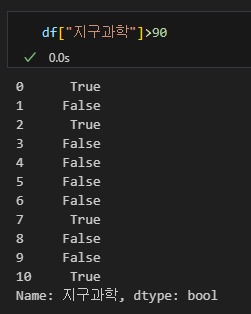
이것을 다시 데이터 프레임으로 집어넣으면 판다스는 True인 행을 출력해주는 방식이다.
# loc을 사용하여 조건문을 쓸 경우(추천)
df.loc[df["지구과학"]>90]
# 조금 더 간단한 방법을 이용할 경우
df[df["지구과학"]>90]
어떠한 방식이든 출력은 크게 다르지 않기에 편한 것을 쓰기를 바란다. 우리의 목표는 판다스가 아니기 때문이다. 먼저 해보고, 오류가 나면 그때 방법을 바꿔도 늦지 않다.
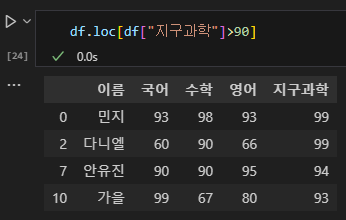
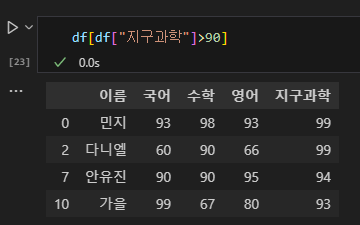
(2) 다중 조건문
여러개의 조건을 주는 것도 가능하다.
df.loc[(df["지구과학"]>90) & (df["영어"]>90)]
두 조건을 모두 만족시키는 값을 찾고 싶다면 두 조건을 괄호로 묶고 사이에 & 기호를 넣어주면 된다. 왜 인지는 모르겠지만 and를 넣으면 오류가 난다.

두 조건 중 하나를 만족시키는 값을 찾고 싶다면 | 를 입력해주면 된다. 마찬가지로 or을 넣으면 오류가 난다.
df.loc[(df["지구과학"]>90) | (df["영어"]>90)]
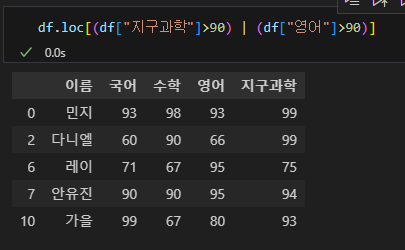
조건에 맞는 값들 중 보고싶은 열만을 조회하는 것도 가능하다.
df.loc[(df["지구과학"]>90) | (df["영어"]>90), ["이름","영어" "지구과학"]]
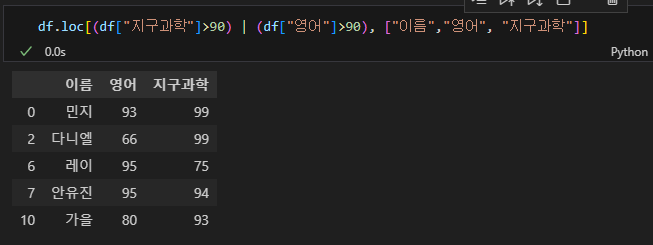
7) 기타 유용한 기능(columns, unique)
데이터 시각화를 할 때 이것이 어떤 자료의 값인지를 범례로 표현해야 할 때가 많다. 이럴 경우에는 columns로 열의 인덱스를 조회하거나, unique 함수로 유일한 값을 리턴 받을 수 있다.
(1) columns
데이터의 열의 인덱스를 조회할 때 사용한다.
df.columns
데이터를 새롭게 호출한 다음 인덱스를 확인해보면 아래와 같은 출력을 볼 수 있다.
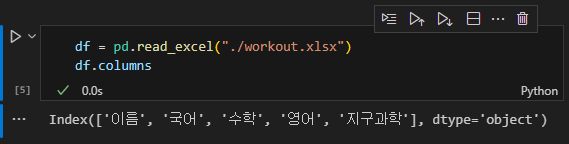
만일 학생들의 이름을 제외한 국어, 수학, 영어, 지구과학 점수를 그래프로 그린다고 할 때, 범례를 모두 타이핑 할 필요 없이 편하게 지정 할 수 있다.
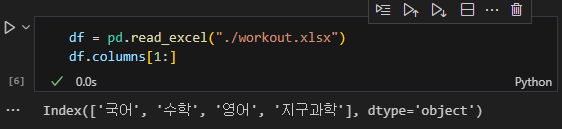
(2) unique
해당 함수는 데이터 값의 중복을 제거하고 유니크한 값만 리턴한다. 먼저 지구과학의 성적을 확인해보자.
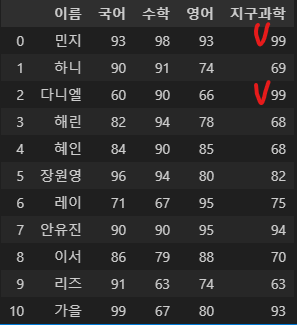
지구과학의 성적의 유니크 한 값을 출력해보자.
df["지구과학"].unique()
해당 코드의 출력을 보면 실제 99점인 학생은 두 명이지만 한개만 들어가 있는 것을 알 수 있다.
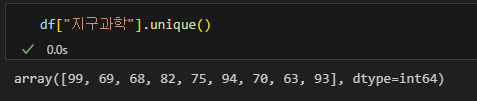
배열의 형태로 리턴하기 때문에 순차적으로 꺼내어 값을 확인해 볼 수도 있다.
3. 글을 마치며
이번 글에서는 Pandas를 이용해 데이터를 처리하는 방법에 대해 알아보았다. 기초적인 내용만 다루었기에 다소 난이도가 쉽게 느껴질 수도 있다. 우리의 첫번째 목표는 데이터 전처리가 아니라 정형화 된 데이터를 시각화하는 것에 있음을 기억하자.
다음 글에서는 간단한 Pandas 연습문제를 한번 풀어보려고 한다.
파이썬 데이터 시각화 입문 3 : Pandas 연습문제
지난 글에서는 Pandas라는 라이브러리로 데이터를 다루는 방법에 대해 다루었다. 오늘은 pandas로 간단한 출력을 해보는 연습 문제를 풀어보려고 한다. 1. 데이터 출처 요즘은 공개된 빅데이터가 많
fecu.tistory.com



